In this article
FunnelStory vs. Claude: Why the Intelligence Graph Beats Raw LLMs
For high-stakes enterprise data, FunnelStory's Intelligence Graph provides consistent, auditable answers, unlike raw LLMs like Claude, which are non-deterministic.

By Preetam Jinka
Co-founder and Chief Architect
Mar 02, 2026
11 min read
Last Updated: Apr 21, 2026
TL/DR - For high-stakes enterprise data tasks, like generating consistent renewal health reports, an agent operating on a structured Customer Intelligence Graph (FunnelStory) is significantly more reliable than an agent running a raw Large Language Model (Claude). A raw LLM is good for finding individual signals ("needles in the haystack"), but it falls short on consistency and completeness when reasoning about the entire dataset ("the whole haystack"). You need a structured data approach for auditable, reproducible enterprise intelligence.
LLMs are good at exploring data to find individual signals — a competitor mention buried in a transcript, a pricing escalation in a call. They fall behind when you need them to reason consistently about the entire dataset.
Not all agents are equal. Trivial agents doing simple tasks — lookups, FAQ, single-document summarization — can be reliable. High-stakes agents are different. A renewal agent needs to analyze a full portfolio, aggregate signals across hundreds of accounts, and produce consistent intelligence that someone (or something) will act on. That requires complex analysis, not simple lookups. You can't rely on "just Claude" for that.
Problems of AI Agents with Enterprise Data
There are two problems with AI Agents over enterprise data:
The state problem (what agents know):
Agents have access to raw knowledge — data logs, transcripts, CRM records — but they have to use runtime inference to convert that into intelligence. That runtime inference is non-deterministic, inaccurate, and imprecise. Ask the same question three times, get three different answers. They also cannot reason about absence: if a champion hasn't emailed in 30 days, an LLM reading raw logs struggles to confidently state that something isn't there.
Recent research confirms this is structural:
Rana & Kumar (arXiv:2512.14474) show that LLM agents fail in complex tasks specifically because of "inconsistent state tracking" — collapsing modeling and reasoning into a single generative process, with state tracked implicitly in text rather than in an explicit model.
Cui & Alexander (arXiv:2602.14349) ran identical prompts at zero temperature across identical datasets 10 times each and found "considerable variation in the analytical results even for consistent configurations" — two agents reaching different conclusions from the same data.
The dynamics problem (how agents behave):
The state problem compounds. When an agent does multi-step reasoning over imprecise runtime inference, errors compound exponentially, yielding completely unreliable behavior. Enterprise workflows are non-linear and stochastic. Because standard agents are just multi-step prompting chains, there is no way to tell how they will behave in new, unexpected, or adversarial scenarios. Deploying them over high-stakes customer relationships without rigorous testing is gambling.
Laban et al. (arXiv:2505.06120) simulated 200,000+ multi-turn conversations and found a 39% average performance drop from single-turn to multi-turn, driven not by a lack of intelligence but by "a significant increase in unreliability" — when an LLM makes an incorrect assumption early, it relies on that incorrect context and doesn't recover.
Huang et al. (arXiv:2505.18878) tested LLM agents on real-world enterprise CRM workflows (B2B sales, support, CPQ) and found performance dropped from ~58% on single-turn tasks to ~35% on multi-turn, concluding there is a "substantial gap between current LLM capabilities and enterprise demands."
We ran a benchmark that directly measures both problems. Same prompt, same data, 3 runs each.
Benchmark Test Setup
Data
Realistic B2B SaaS data in PostgreSQL: 65 accounts, ~$2M ARR, 473 meeting transcripts, CRM activity logs, and account metadata (renewal dates, ARR, domains). The distribution is realistic — healthy expansions, quiet accounts, active churn risks, and silent churn risks.
The benchmark dataset is publicly available.
This is a simpler, cleaner dataset than what we see in production. Real enterprise data is messier: inconsistent schemas, dirty data, higher volume, more edge cases. In production, we've seen Claude and other foundation models exhibit even more variance. This benchmark is a lower bound.
Prompt
Both systems received the same prompt, run 3 times each:
Give me a report of: upcoming renewals. I need health (low, medium, high chance of churn or retention. or neutral. 7 possible bands).
Then summary of
- feature requests
- competitor mentions
- bugs or issues
- personnel changes
For each I need number of occurrences and accounts.
Provide as markdown.System A: Claude Sonnet 4.6 + PostgreSQL MCP
Claude connects directly to the Postgres database via Zapier MCP. Full access to all tables: accounts, meetings, activities. No pre-computed intelligence. It reads raw data and reasons over it.
System B: FunnelStory
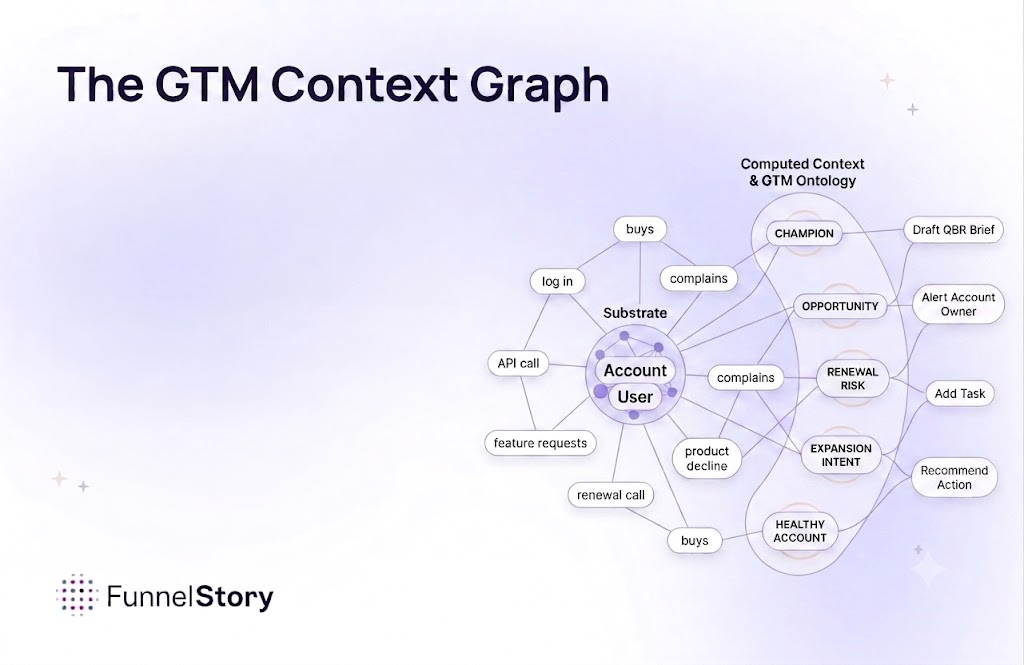
Same underlying data, processed through FunnelStory's Customer Intelligence Graph. The graph adds: prediction scores (0–100 health), needle movers (labeled signals: competitor, feature request, bug, personnel change), and structured account metadata. The FunnelStory agent queries the graph: it reads facts, not raw transcripts. FunnelStory agents are hardened through simulation and evals to traverse the graph and handle edge cases across various shapes of enterprise data.
Benchmark Testing Results
We ran the same prompts with both FunnelStory and Claude 3 times each, and the table below provides the final benchmark results.
FunnelStory | Claude (Sonnet 4.6 + PostgreSQL MCP) | |
|---|---|---|
Prediction accuracy | 🟢 100% (13/13, every run) | 🔴 62–85% (varies by run) |
Signal count consistency | 🟢 100% (identical across 3 runs) | 🔴 0/3 runs in agreement |
Health band consistency | 🟢 100% (same score, same band every run) | 🔴 0/3 runs in agreement |
High-risk accounts detected | 🟢 6/6 (all three runs) | 🔴 2/6 consistent across runs |
Silent churn detection | 🟢 Detected (score ~30) | 🔴 0/3 runs detected |
The State Problem: Unreliable Answers with Claude
We scored both systems against 13 accounts with unambiguous expected outcomes: 6 accounts with clear high-churn signals, 6 accounts with clear retention signals, and 1 silent churn risk.
System | Run 1 | Run 2 | Run 3 |
|---|---|---|---|
FunnelStory | 13/13 (100%) | 13/13 (100%) | 13/13 (100%) |
Claude | 9/13 (69%) | 8/13 (62%) | 11/13 (85%) |
FunnelStory classified every account correctly, every run. Claude ranged from 62% to 85%. Wonka Industries was never classified as High Churn despite a director-level TCO comparison. Kramerica was missed every run. S.H.I.E.L.D. and Cyber Corp shifted between Medium and High depending on the run.
The accuracy gap comes from how each system arrives at answers.
A question like "how many feature requests do we have across renewing accounts?" should have one answer. It doesn't, with Claude.
Run | Feature Requests | Competitors | Bugs/Issues | Personnel |
|---|---|---|---|---|
Claude 1 | 7 FRs in 7 accounts | 3 mentions in 3 accounts | 6 mentions in 6 accounts | 8 mentions in 8 accounts |
Claude 2 | 17 FRs in 9 accounts | 3 mentions in 3 accounts | 27 mentions in 9 accounts | 11 mentions in 6 accounts |
Claude 3 | 11 FRs in 5 accounts | 4 mentions in 4 accounts | 15 mentions in 6 accounts | 6 mentions in 4 accounts |
FunnelStory 1 | 16 FRs in 5 accounts | 2 mentions in 2 accounts | 18 mentions in 8 accounts | 8 mentions in 6 accounts |
FunnelStory 2 | 16 FRs in 5 accounts | 2 mentions in 2 accounts | 18 mentions in 8 accounts | 8 mentions in 6 accounts |
FunnelStory 3 | 16 FRs in 5 accounts | 2 mentions in 2 accounts | 18 mentions in 8 accounts | 8 mentions in 6 accounts |
FunnelStory: identical across all three runs. Claude: varies up to 4.5x (bugs: 6 vs 27).
The question is: why does Claude behave the way it does?
Claude has access to raw information (meeting transcripts, CRM records) but has to use runtime inference to convert that into intelligence: what counts as an "occurrence," how to define health bands, which accounts to scope. That runtime inference is non-deterministic. It re-derives what "occurrence" means each time: sometimes per transcript mention, sometimes per account, sometimes per theme.
On the other hand, FunnelStory's Intelligence Graph has already resolved the ambiguity in the pipeline. A needle mover is a row. An occurrence is a row. The agent counts rows, not interpretations.
Same issue with health bands.
Claude invented different band schemes across runs — 5 bands, 7 bands, different names — and shifted accounts between them. For example, for Wonka Industries, Claude provides three different answers in three different runs
Run 1: Low churn
Run 2: Leaning churn
Run 3: Medium churn
On the other hand, FunnelStory maps prediction_score to 7 canonical bands deterministically. Same account, same score, same band, every time.
Reasoning About Absence: The Kramerica Case
Kramerica is the hardest account in the dataset. Renewing in 14 days. Some usage (automated workflow runs), but zero meetings, zero human engagement. There's nothing to read in a transcript because there are no transcripts.
Run | Kramerica Classification |
|---|---|
Claude 1 | Neutral — "No meeting data available; unknown health" |
Claude 2 | Neutral — "No meeting data available; unknown health" |
Claude 3 | Neutral — "No meetings found in data. Insufficient signal." |
FunnelStory 1 | 30.5 — Low churn risk |
FunnelStory 2 | 30 — Low churn risk |
FunnelStory 3 | 30.5 — Low churn risk |
Kramerica had activity, but not the kind that matters for retention. Automated workflow runs are background noise. What correlates with retention: PRs merged, issues created, meetings held. Kramerica had none of that.
FunnelStory's prediction models know what healthy accounts look like and do. They've learned what good vs bad engagement means. When they see Kramerica — activity, but the wrong kind — they flag it. Claude looked at Kramerica in isolation. It has no model of what healthy accounts do. No meetings? "No signal." It couldn't distinguish "no activity" from "wrong kind of activity" because it doesn't have that normative understanding.
This is the state problem in its purest form: the ability to reason about absence. An LLM reading raw logs struggles to confidently state that something isn't there. The Intelligence Graph surfaces what is absent (gaps), not just what is present.
The Dynamics Problem: Unreliable Behavior
The state problem compounds. This benchmark is a single-step task — one prompt, one report. Even so, Claude produced different answers every run. Now imagine multi-step reasoning: the agent runs a renewal report, identifies at-risk accounts, drafts escalation emails, and updates the CRM. Each step's imprecise inference feeds into the next. Errors compound exponentially.
If an agent ran this report every Monday and triggered save motions based on the results, which accounts get escalated? With Claude, it depends on the run. Monday: escalate A and B. Tuesday: escalate C and D. Same data, different behavior.
Enterprise workflows are non-linear and stochastic. Standard agents are multi-step prompting chains — there is no way to tell how they will behave in new, unexpected, or adversarial scenarios. Deploying them over high-stakes customer relationships without rigorous testing is gambling. And that's with clean data. In production, with messy schemas and higher volume, we've seen even more variance.
Where Claude Does Well
Claude did well when things are obvious. Black Mesa's pricing ultimatum — competitor quote at 1/3 the price, CFO involved — Claude caught that every run. Same for Umbrella Corp's compliance deadline. The healthy accounts with clear expansion signals — both systems agree completely.
Account | Risk Signal | Claude (Varies by Run) |
|---|---|---|
Black Mesa | Competitor quote at 1/3 the price, CFO involved | High Churn |
Umbrella Corp | Compliance deadline: fix audit trail by Q1 or switch | High Churn |
Cyberdyne Systems | CTO ordered competitor comparison | High Churn |
S.H.I.E.L.D. | Feature backlog >1yr, P1 SLA failures, pricing escalation | Medium to High (varies) |
Cyber Corp | Feature backlog >1yr, leadership escalation | Medium to High (varies) |
Wonka Industries | TCO comparison escalated to director | Low to Medium (varies) |
When signals are loud enough, Claude finds them. The problem: when it's less obvious, or when you need consistency across the whole dataset, it falls short. Wonka went from Low to Leaning Churn to Medium depending on the run. S.H.I.E.L.D. swung between Medium and High.
LLMs are good at exploring to find needles. The problem is consistency and completeness when you need to reason about the whole haystack.
Why FunnelStory Outperforms Claude
FunnelStory decouples deterministic state from probabilistic reasoning.
The Customer Intelligence Graph (solving unreliable answers).
FunnelStory ingests data from 37+ sources and pre-computes the intelligence — health scores, churn factors, gaps — in the pipeline. The agent does not do math or guess at runtime. It queries the graph. The same query always yields the same, auditable answer. We surface what is absent, not just what is present.
LLMs are at the end of the pipeline, not at the forefront.
The FunnelStory agent reads from the Intelligence Graph — pre-computed state, canonical definitions, prediction scores. The LLM synthesizes and formats what's already been resolved. With Claude over MCP, the LLM is at the forefront: it has to figure out schema, join logic, counting definitions, and band thresholds from scratch every time.
FunnelStory agents are hardened through simulation and evals.
Before an agent ever touches a live account, it operates in our simulator. We run agents through thousands of generated scenarios, including rare ones. Claude over MCP is improvising every time.
Overall Comparison Results
Dimension | FunnelStory (Intelligence Graph) | Claude (raw LLM) |
|---|---|---|
Prediction accuracy | 100% (13/13, every run) | 62–85% (varies by run) |
Consistency | Identical output across 3 runs | Different numbers every run (up to 4.5x variance) |
Health Scores | Deterministic, numeric, reproducible | Qualitative, varies by run |
Silent risk detection | ML models encode norms; detect "wrong kind of activity." | No model of healthy accounts; looks at each account in isolation |
Signal Counting | Structured: 1 occurrence = 1 labeled signal in the graph | Ambiguous definition, changes per run |
Auditability | SQL queries against a structured graph (fully traceable) | Natural language rationale (non-reproducible) |
Benchmark conducted in February 2026. Claude Sonnet 4.6 with PostgreSQL MCP. Dataset: 65 accounts, ~$2M ARR, 473 meeting transcripts, CRM activity logs. Each system ran the same prompt 3 times. FunnelStory agent operates on an Intelligence Graph built from the same underlying data available to Claude.
Closing
If you ask your data warehouse the same question twice, you expect the same answer. That should be true whether the question comes from SQL or natural language — and especially if an agent is going to act on it. That is what FunnelStory achieves with its Customer Intelligence Graph, and that is going to be a model for any long-term enterprise deployment.